The simple idea behind normalization
Deep learning models move numbers through many layers. Those numbers can be word embeddings, image features, hidden activations, attention outputs, or anything else the model is learning from.
The problem is that those numbers do not always stay well behaved.
Some layer might produce values like this:
[2.0, 4.0, 6.0]Another layer might produce:
[200.0, 400.0, 600.0]The pattern is similar, but the scale is completely different. Neural networks are sensitive to scale. If activations become too large, gradients can explode. If they become too tiny, gradients can vanish. Either way, training becomes slow, unstable, or just plain annoying.
Normalization is the idea of rescaling values so they live in a more controlled range.
Most normalization methods do a version of this:
normalized_value = (value - mean) / standard_deviationAfter that, the values usually have:
- mean close to
0 - standard deviation close to
1 - a scale that is easier for the next layer to handle
A tiny example
Take this vector:
[2, 4, 6]The mean is:
(2 + 4 + 6) / 3 = 4The values are 2 below the mean, exactly at the mean, and 2 above the mean. After normalization, the vector becomes roughly:
[-1.22, 0.00, 1.22]The important thing is not the exact decimal. The important thing is that the vector is now centered and scaled.
Then the model usually applies two learned parameters:
output = gamma * normalized_value + betaWhy do we normalize and then let the model scale and shift again?
Because normalization gives the network a stable starting point, while gamma and beta let the network decide the best final scale for the task. In other words: we clean the numbers, but we do not remove the model's freedom.
Why this helps training
Normalization helps in three practical ways.
First, it improves training stability. Extreme activations can lead to extreme gradients, and extreme gradients make optimization jump around. Normalization keeps values in a friendlier range.
Second, it often makes training converge faster. If every layer receives values on a predictable scale, the optimizer does not need to constantly adapt to wildly changing activation sizes.
Third, it reduces what people call internal covariate shift. That phrase sounds heavy, but the intuition is simple: while earlier layers are learning, the distribution of values passed to later layers keeps changing. Normalization reduces how chaotic those changes feel to the next layer.
So the goal is clear:
keep activations numerically calm while the model learnsThe big question is where we calculate the mean and standard deviation.
That is where batch normalization and layer normalization differ.
Batch normalization: normalize feature by feature across the batch
Imagine we are training a model on a batch of examples. Each example has three features:
sample 1: [6.5, 2.4, 3.2]
sample 2: [2.1, 0.4, 3.6]
sample 3: [7.5, 9.2, 1.5]
sample 4: [2.2, 1.1, 6.7]Batch normalization looks vertically.
For feature d1, it uses:
[6.5, 2.1, 7.5, 2.2]For feature d2, it uses:
[2.4, 0.4, 9.2, 1.1]For feature d3, it uses:
[3.2, 3.6, 1.5, 6.7]So batch normalization means:
for each feature, calculate statistics across the batchThat works beautifully in many computer vision models. If a batch contains many images of the same shape, each channel has enough meaningful values to estimate useful statistics. Batch normalization became popular because it made deep convolutional networks much easier to train.
But transformers usually work with sequences, and sequences are messier.
The sequence problem: sentences do not have equal length
Suppose we want to train a transformer on these two sentences:
Hi Nitish
How are you todayThe first sentence has 2 tokens. The second sentence has 4 tokens.
Models like tensors with consistent shapes, so we pad the shorter sentence:
Hi Nitish <padding> <padding>
How are you todayNow both rows have 4 token positions.
That padding is useful for batching, but it is not real language. It is just filler.
The attention mask tells the transformer:
do not treat padding as meaningful contentBut if a normalization method calculates statistics across the batch without respecting the true sequence lengths, the padding values can contaminate the mean and variance.
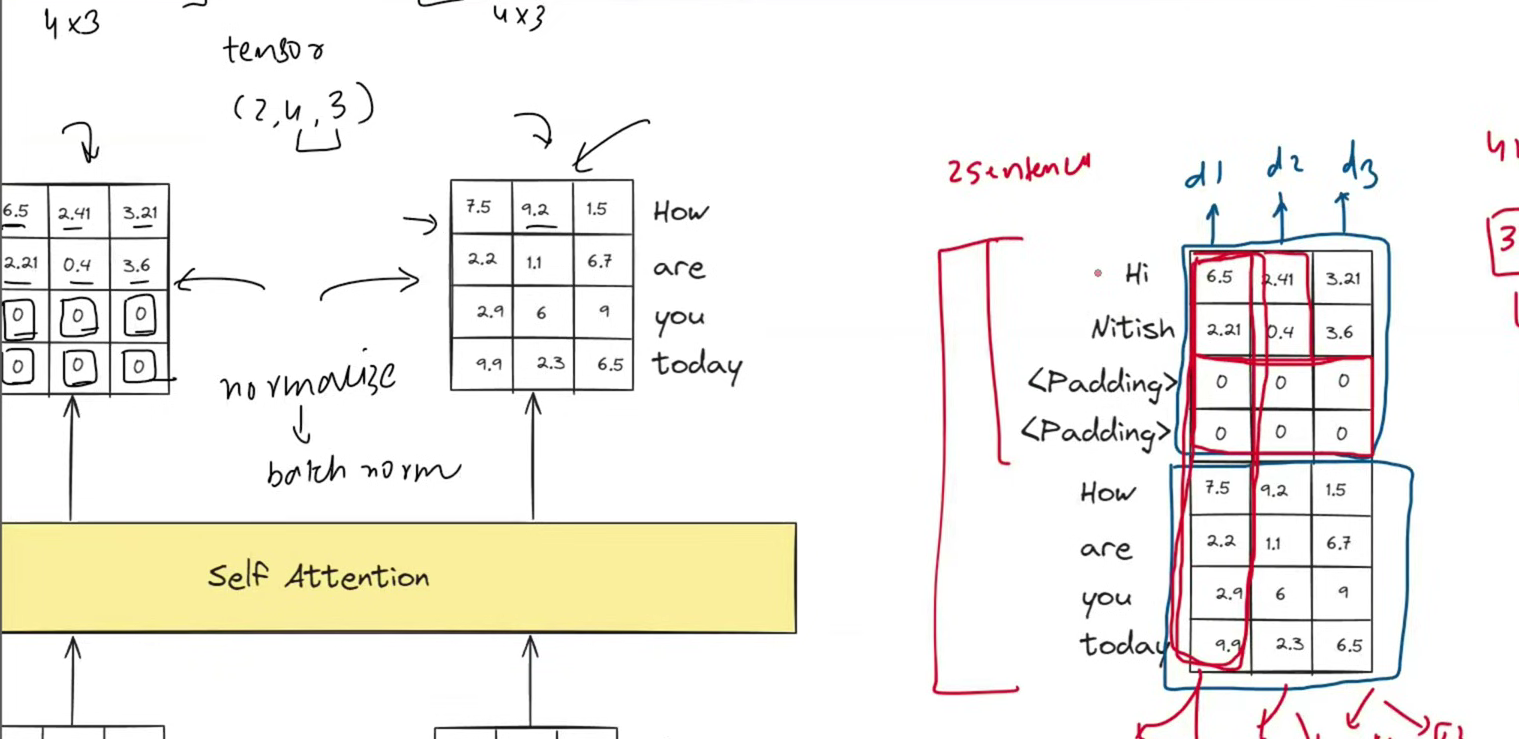
Where batch norm gets awkward in transformers
Let us use a small hidden size of 3 so the numbers fit on the page.
Imagine the token Hi has this activation vector:
Hi = [6.5, 2.4, 3.2]The token Nitish has:
Nitish = [2.1, 0.4, 3.6]The padding positions might be represented as zeros:
<padding> = [0, 0, 0]
<padding> = [0, 0, 0]Now look at just the first feature, d1, for this padded sentence:
[6.5, 2.1, 0, 0]The real tokens suggest a mean of:
(6.5 + 2.1) / 2 = 4.3But if the padding zeros are included, the mean becomes:
(6.5 + 2.1 + 0 + 0) / 4 = 2.15That is a very different statistic.
The model is now normalizing real words using a mean that was pulled down by fake tokens.
This is the core reason batch normalization is a poor default for transformer language models:
sequence batches contain padding, and padding should not shape the statistics for real tokensTo be precise, batch normalization does not magically "fail" in every possible sequence model. You can design masked variants, use careful implementations, or apply it in places where the shape makes sense. But the standard transformer setup wants something simpler and more reliable.
It wants normalization that does not depend on other examples in the batch.
That is layer normalization.
Layer normalization: normalize one token at a time
Layer normalization looks horizontally.
Instead of asking:
what are all the values for feature d1 across the batch?it asks:
what are all the feature values inside this one token vector?For the token:
Hi = [6.5, 2.4, 3.2]Layer normalization calculates the mean and standard deviation across those three features.
Mean:
(6.5 + 2.4 + 3.2) / 3 = 4.03Then it normalizes each value in that same vector. The exact normalized result is roughly:
[1.39, -0.92, -0.47]The key idea:
the token is normalized using its own features onlyNo other sentence is needed. No other batch item is needed. Padding from another position does not affect the statistics for Hi.
In a transformer, the hidden state usually has this shape:
[batch_size, sequence_length, hidden_dimension]Layer normalization operates across hidden_dimension for each token position.
So for every token at position (batch_index, token_index), it normalizes across that token's embedding features.
That is why layer norm fits transformers so naturally.
A classroom analogy
Imagine a teacher wants to make exam scores easier to compare.
Batch normalization is like saying:
For question 1, compare every student's score on question 1.
For question 2, compare every student's score on question 2.
For question 3, compare every student's score on question 3.That is fine if every student answered every question.
But now imagine some students had blank questions because their exam was shorter. If those blanks are counted as zero, the class average becomes misleading.
Layer normalization is like saying:
For each student, normalize across that student's own answered questions.The student's score is adjusted based on their own row of values, not on the blanks from someone else's paper.
That is the transformer situation. Sentences have different lengths, so padding is common. Layer normalization avoids letting padding-heavy examples distort the statistics for real tokens.
A concrete transformer example
Take this mini batch:
sentence A: Hi Nitish <padding> <padding>
sentence B: How are you todaySuppose each token has 3 hidden features.
Batch normalization for feature d1 may look down a column or across a batch-like dimension:
d1 values = [6.5, 2.1, 0, 0, 7.5, 2.2, 2.9, 9.9]The two zeros are padding. They are not words. But they still pull the mean downward if the implementation does not mask them out.
Layer normalization for Hi uses only:
[6.5, 2.4, 3.2]Layer normalization for Nitish uses only:
[2.1, 0.4, 3.6]Layer normalization for How uses only:
[7.5, 9.2, 1.5]Each token gets cleaned independently.
That independence is extremely useful in transformers because the batch is just a training convenience. The model should understand Hi the same way whether it happens to be batched with a short sentence, a long sentence, or a paragraph full of padding.
Why layer norm is also good for residual connections
Transformers do not just stack attention layers directly. They use residual connections:
output = x + sublayer(x)The residual path helps information and gradients flow through deep networks. But it also means values from different paths are repeatedly added together. Without normalization, the scale of hidden states can drift as the network gets deeper.
Layer normalization keeps the residual stream stable.
The original transformer used a pattern often called post-norm:
x = LayerNorm(x + Sublayer(x))Many modern large language models use a pre-norm style:
x = x + Sublayer(LayerNorm(x))The exact placement can differ, and some models use related variants like RMSNorm. But the principle is the same:
normalize each token's hidden vector so the transformer stack stays trainableBatch norm vs layer norm in one table
| Question | Batch normalization | Layer normalization |
|---|---|---|
| What does it normalize across? | The batch dimension for each feature | The feature dimension for each token or sample |
| Does one example depend on other examples? | Yes | No |
| Is it sensitive to batch size? | Yes | Much less |
| What happens with sequence padding? | Padding can corrupt batch statistics unless handled carefully | Real token statistics are independent of padding in other positions |
| Common use case | CNNs and fixed-shape activations | Transformers, RNNs, and sequence models |
| Mental picture | Vertical normalization | Horizontal normalization |
The important caveat
It is tempting to say:
batch norm is bad, layer norm is goodThat is too simple.
Batch normalization is excellent in the right setting. It has powered many successful vision models.
Layer normalization is excellent in the transformer setting because transformers process variable-length sequences, rely heavily on residual streams, and often train with batch sizes where batch statistics may be noisy.
So the better rule is:
use the normalization method that matches the shape of your dataFor fixed-size image batches, batch norm can be a great fit.
For token sequences, layer norm usually fits better.
The simplest mental model
If you forget everything else, remember this:
Batch normalization asks:
How does this feature compare with the same feature in other examples?Layer normalization asks:
How does this value compare with the other features inside the same token?Transformers prefer the second question because each token should be normalized using its own hidden vector, not statistics polluted by unrelated sentences or padding tokens.
That is why layer normalization became the standard normalization choice in transformers.