The distinction that confuses almost everyone
When people first learn transformers, they often hear two phrases:
- self-attention
- multi-head attention
Those phrases sound like two separate ideas, almost like the model must choose one or the other.
That is the first misunderstanding to clear up.
In transformer models, the common pattern is actually multi-head self-attention.
That means:
- the model attends over the same sequence it is currently processing
- it does that with multiple attention heads in parallel
So self-attention and multi-head attention are not enemies. They describe two different aspects of the same mechanism:
- self-attention tells you where the queries, keys, and values come from
- multi-head tells you how many attention computations run at once
If you only remember one sentence from this post, remember this:
Self-attention lets a token look at other tokens in the same sequence. Multi-head attention lets it do that from several learned perspectives instead of just one.
Why self-attention exists in the first place
Before we talk about multi-head attention, we need to refresh the job of self-attention itself.
Language is contextual. A word does not always mean the same thing in every sentence.
For example, the word bank in:
I deposited cash at the bank.does not mean the same thing as bank in:
We sat on the bank of the river.Older static embeddings struggle with this because each word starts with one fixed vector. Self-attention improves on that by letting the model look at surrounding words and build a context-aware representation.
That is why self-attention matters: it helps the model produce contextual embeddings instead of static ones.
A simple recap of self-attention
Suppose the input sequence is represented by a matrix X.
The model creates three projections:
Q = XW_Q
K = XW_K
V = XW_VThen it computes:
Attention(Q, K, V) = softmax((QK^T) / sqrt(d_k)) VHere is the intuition:
- Query asks: what am I looking for?
- Key asks: what information do I offer?
- Value is the information I can contribute to the final representation
If a token's query and another token's key match strongly, the second token gets more influence in the weighted sum.
That is self-attention in its simplest form.
The important correction: self-attention does not automatically mean one head
This point is subtle but important.
People often explain self-attention using a single diagram and then later explain multi-head attention as if it replaces self-attention.
It does not.
You can have:
- single-head self-attention
- multi-head self-attention
The word self refers to the fact that the sequence attends to itself. The word head refers to how many attention computations happen in parallel.
So the real comparison is not:
- self-attention vs multi-head attention
It is more accurately:
- single-head self-attention vs multi-head self-attention
That is the version we will compare in the rest of this post.
What goes wrong with just one attention head
A single attention head can learn useful relationships. The problem is not that it is useless. The problem is that it is too narrow for complex language.
A single head gives the model one attention pattern at that layer for that projection space.
Language, however, contains many relationships at once:
- who did the action
- who received the action
- which adjective modifies which noun
- which pronoun refers to which entity
- which phrase expresses cause
- which phrase expresses time
- which words are semantically related even when far apart
One head has to compress all of that into one set of scores.
That is the bottleneck.
A classic ambiguity example
Take the sentence:
The man saw the astronomer with a telescope.There are multiple plausible interpretations:
- the man used a telescope to see the astronomer
- the astronomer was the one holding the telescope
Even beyond that ambiguity, the sentence contains several relationships at once:
- man is linked to the subject role
- saw is the main action
- astronomer is the object
- with introduces a modifying phrase
- telescope is the key noun in that phrase
If we use only one attention head, the model may heavily favor one interpretation and under-represent the other. It can still learn something useful, but it has limited room to keep multiple perspectives alive simultaneously.
That is exactly why multi-head attention helps.
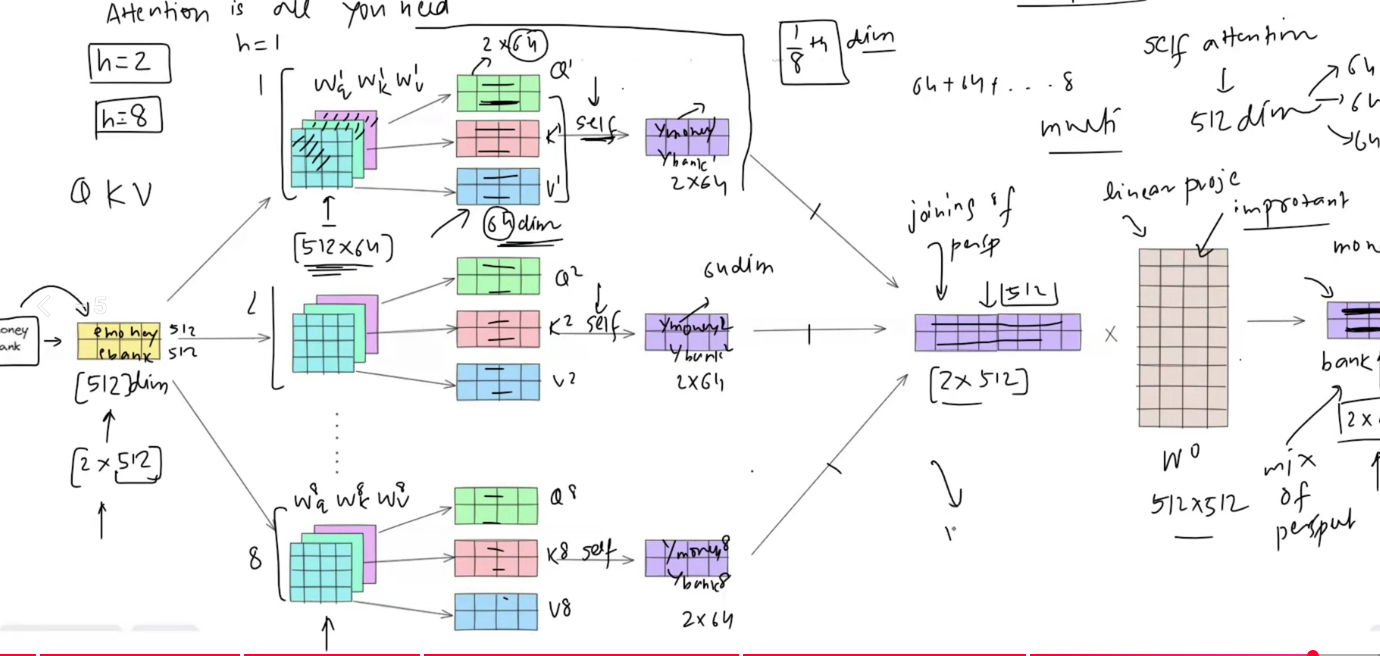
What multi-head attention actually does
Multi-head attention runs several self-attention operations in parallel.
Instead of learning one set of projections, the model learns one set per head:
W_1^Q, W_1^K, W_1^V
W_2^Q, W_2^K, W_2^V
...
W_h^Q, W_h^K, W_h^VEach head computes:
head_i = Attention(XW_i^Q, XW_i^K, XW_i^V)Then the outputs are combined:
MultiHead(X) = Concat(head_1, head_2, ..., head_h) W^OThat final matrix W^O is important. It mixes the information from all heads back into one unified representation.
So the full story is:
- project the same input into multiple learned subspaces
- run self-attention separately inside each subspace
- concatenate the outputs
- project the result back to the model dimension
This is what gives transformers more expressive power.
Why this helps so much
The big win is not that each head sees different tokens by force. The win is that each head gets the chance to learn a different useful pattern.
In practice, heads often specialize in different types of structure, such as:
- local grammatical relations
- subject-verb or noun-modifier patterns
- long-range dependencies
- pronoun resolution
- semantic similarity
- task-specific cues useful for translation or summarization
Not every head becomes perfectly interpretable, and not every head is equally important. But the architecture gives the model room to represent multiple relationships instead of collapsing them into one.
A concrete mental model
Imagine asking one person to summarize a football match, a weather report, and a legal contract all at once in one sentence. They may capture something, but important details will be lost.
Now imagine asking several specialists to each focus on one aspect, then combining their notes into a final summary.
That is roughly what multi-head attention does for a sentence:
- one head can focus on syntax
- one on semantic similarity
- one on long-range dependency
- one on entity tracking
Then the model merges those partial views into one richer representation.
A worked shape example
Suppose:
d_model = 512
number of heads = 8
d_head = 64
sequence length = 5Then the input has shape:
X : [5, 512]Each head receives the same input X, but uses different learned projection matrices:
head_1 = Attention(XW_1^Q, XW_1^K, XW_1^V) -> [5, 64]
head_2 = Attention(XW_2^Q, XW_2^K, XW_2^V) -> [5, 64]
...
head_8 = Attention(XW_8^Q, XW_8^K, XW_8^V) -> [5, 64]After concatenation:
Concat(head_1, ..., head_8) : [5, 512]Then the model applies:
[5, 512] W^O -> [5, 512]That is why multi-head attention does not simply explode the representation size forever. It widens temporarily across heads, then returns to the original model dimension.
Why split into smaller heads instead of making one giant head
This is another common question.
Why not just keep one large head with all 512 dimensions?
Because one large head still gives you only one attention pattern.
The model may have a big vector space, but it still has one set of scores and one weighted sum for that head. Multi-head attention instead creates multiple smaller subspaces, each with its own learned projections and its own attention pattern.
That is the real value.
So the purpose is not just dimensionality reduction. It is diversity of learned attention behavior.
The smaller per-head size is what makes that diversity computationally practical.
A sentence-level example: what different heads might learn
Let us come back to:
The man saw the astronomer with a telescope.Imagine a model with four heads.
Head 1 might focus on the main action:
saw -> manHead 2 might focus on the direct object:
saw -> astronomerHead 3 might focus on the prepositional phrase:
with -> telescopeHead 4 might track the possible modifier attachment:
astronomer -> telescopeA single head would have to compress all of those into one weighting pattern. Multi-head attention lets the model keep several candidate relationships active at the same time.
Another example: coreference
Consider:
Sara gave Maya her notebook because she trusted her.This sentence is difficult because there are two pronouns and multiple possible references.
Different heads can help the model track:
- who the subject is
- who the receiver is
- which entity each pronoun most likely refers to
- how the causal phrase changes the meaning of the sentence
A single head can struggle to keep all of those signals organized. Multiple heads make that much easier.
Another example: translation
Suppose the model is translating:
The animals didn't cross the street because they were tired.Different heads may focus on different clues:
- one head tracks that they refers to animals
- one head tracks the negation in didn't
- one head tracks the causal role of because
- one head tracks the long-range relation between tired and didn't cross
This is one reason transformers became so effective in machine translation. They do not have to flatten all structure into one path through time the way older sequence models often did.
Another example: summarization
In summarization, not every useful relationship is the same kind of relationship.
Different heads may focus on:
- who or what the document is mainly about
- repeated entities across paragraphs
- factual statements versus descriptive filler
- sentence-to-sentence transitions
- temporal order of events
When those signals are combined, the model gets a stronger representation of what should survive into the summary.
What the final output projection W^O is doing
This part is easy to overlook.
After the model concatenates all head outputs, it applies a linear layer W^O.
That projection is not just a cosmetic final step. It helps the model:
- combine information across heads
- reweight what each head discovered
- map the concatenated representation back into the model's working space
So multi-head attention is not only "many heads side by side." It is also a learned merge step after those heads finish.
Without W^O, the model would have a set of parallel outputs but no learned way to integrate them cleanly.
A common misunderstanding: different heads are not manually assigned roles
We often explain multi-head attention by saying:
- one head learns syntax
- one learns semantics
- one learns long-range relations
That is useful intuition, but it is still only intuition.
The model is not hand-programmed to assign these jobs. The heads learn through training. Some become interpretable. Some do not. Some may even appear redundant.
So it is better to say:
multi-head attention gives the model the capacity to learn multiple kinds of relationships in parallel
rather than claiming every head always has a clean human-readable role.
Self-attention, multi-head attention, and cross-attention are not the same thing
While we are here, one more distinction helps.
| Mechanism | Where do Q, K, V come from? |
|---|---|
| Self-attention | Q, K, and V come from the same sequence |
| Cross-attention | Q comes from one sequence, while K and V come from another |
| Multi-head attention | Multiple heads are used, but each head can be self-attention or cross-attention depending on where Q, K, V come from |
So multi-head attention is not opposed only to self-attention. It is a structural pattern that can be used in different attention settings.
That said, when people talk about the core transformer block, they are often referring to multi-head self-attention.
Why transformers rely on multi-head attention
Transformers work well because language is not one-dimensional.
Words participate in many relationships at the same time:
- syntax
- semantics
- entity tracking
- local context
- long-range context
- causal structure
- temporal structure
If a model had only one head, it would have to squeeze all of that into one attention map.
Multi-head attention gives the model a better way to distribute the work. Each head does not need to solve language completely. It only needs to become useful in one learned way.
That division of labor is one of the reasons transformers scale so well across tasks like:
- machine translation
- summarization
- question answering
- text generation
- document understanding
So what is the real difference?
Here is the cleanest summary:
| Term | What it means |
|---|---|
| Self-attention | A token attends to other tokens in the same sequence |
| Single-head self-attention | The model does that once with one attention pattern |
| Multi-head self-attention | The model does that several times in parallel with different learned projections |
So if someone asks:
How is multi-head attention different from self-attention?
the best answer is:
multi-head attention is not replacing self-attention. It is multiple self-attention heads running in parallel so the model can capture more than one relationship at the same time.
Try it yourself
If you want to make this feel real instead of theoretical, try the Colab playground:
Try the playground in Google Colab
A good way to use it:
- first inspect the shape of the input embedding matrix
- then look at how each head creates its own Q, K, and V
- then compare the per-head outputs
- finally see how concatenation and
W^Orecover one unified output
Once you see those steps, the phrase multi-head self-attention stops sounding abstract and starts feeling mechanical and intuitive.
If you remember one thing
Self-attention gives a token context by letting it look at other tokens in the same sequence.
Multi-head attention makes that process much more powerful by letting the model perform several different self-attention computations at once, each in a different learned subspace, and then combine them into one richer final representation.
That is why transformers do not stop at one head. Language usually needs more than one perspective.